LoadDataReverse
Alto DBFlute のパートです。
- LoadDataReverseとは?
- 利用方法 (TSVファイル)
- 出力されるテーブルの順番は?
- 日付調整のoriginDateを自動同期
- いろいろな考慮
- 利用方法 (エクセルファイル)
- 細かい仕様
- 単に出力するだけの利用も
- 利用方法の歴史的変遷
- 厳密なデータダンプではない
LoadDataReverseとは?
DB上のデータを、エクセルやTSVなどのデータファイルとして出力する機能です(@since 0.9.8.4)。
主に以下の二つの目的があります。
- ReplaceSchema導入のために、既存データベースからテストデータの抽出
- ReplaceSchema をまだ導入していない場合に、LoadDataReverse で既存のテストデータベースからテストデータを抽出して、そのまま ReplaceSchema のデータにするとスムーズに導入ができるでしょう。
- 画面で登録したデータを ReplaceSchema で利用する "循環テストデータ運用" ができるように
- アプリ画面でデータ登録して LoadDataReverse で抽出して ReplaceSchema する、というような流れの 循環テストデータ運用 を LoadDataReverse で実現できます。
- 整合性のとれたテストデータを手動で作成していくのは大変な作業です。 既に信頼できるアプリの画面があるのであれば、その画面で登録したデータをTSVやエクセルにできれば、効率的にテストケースを増やしていけます。 アプリが完璧でないにしても、出力後に人が目視で確認して業務的な微調整をすれば良いでしょう。それは同時にアプリの動作レビューにもなります。
LoadDataReverse概念図
図 : LoadDataReverse概念図
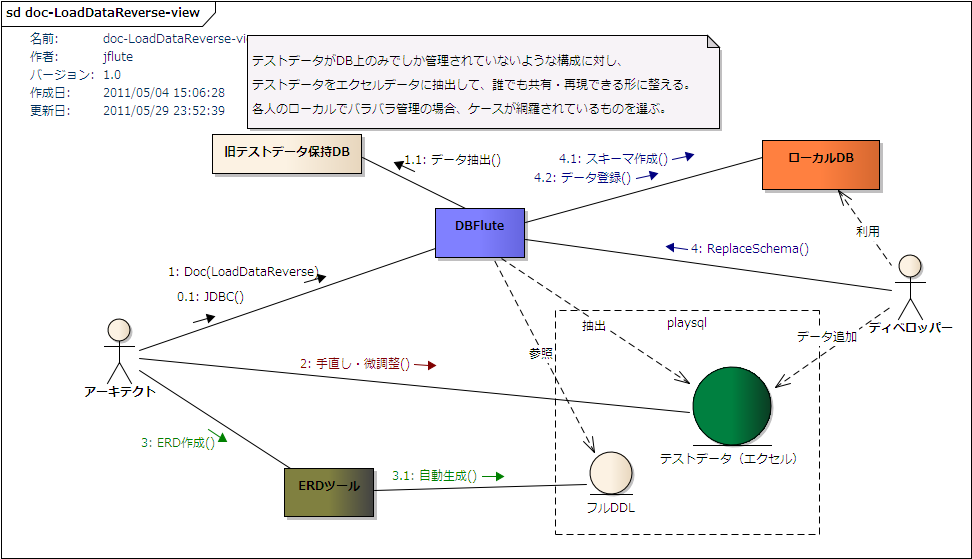
(テストデータは、エクセルファイルだけでなくTSVファイルもサポートしています)
(最近身の回りではすっかりTSVファイルを使っていますね)
利用方法 (TSVファイル)
ここでは、ReplaceSchemaで循環テストデータ運用することを前提として説明します。
dfpropで出力設定
documentMap.dfprop の loadDataReverseMap を有効にして、isReplaceSchemaDirectUse (@since 1.0.4B) を true にします。 (recordLimit は -1 で)
e.g. 単に出力するだけの設定 @documentMap.dfprop
...
; loadDataReverseMap = map:{
# 1テーブルにおける出力するレコード数のリミット (-1は制限なし)
; recordLimit = -1
# ReplaceSchemaのディレクトリに直接出力するか? (循環テストデータ運用)
; isReplaceSchemaDirectUse = true
# それぞれのテーブルのデータを既存ファイルに上書き出力するかどうか?
; isOverrideExistingDataFile = false
# loadingControlMapのoriginDateを自動同期するか?
; isSynchronizeOriginDate = false
# TSVファイルで出力するかどうか? (DBFlute-1.2.9より)
; isDelimiterDataBasis = true
# 0にするとTSVファイルで出力されるようになる (DBFlute-1.2.8まで)
#; xlsLimit = 0
}
...
TSVファイルで出力するためには、DBFlute-1.2.9以降なら isDelimiterDataBasis をtrueに。1.2.8までなら xlsLimit を0に設定します。
manageタスクで叩く
そして、Manageタスクで LoadDataReverse を実行します(@since 0.9.9.7B)。
e.g. Manageタスクで LoadDataReverse の実行 (シェル) @Command
...$ sh manage.sh load-data-reverse
or
...$ sh manage.sh // Enter, and then select the number
reversetsvに出力される
すると、DB上のデータがreversetsv/UTF-8配下に出力されます(@since 1.0.4B)。 reversetsvは、通常のReplaceSchemaでのtsvディレクトリとは違い、LoadDataReverse専用のディレクトリとなります。
- 出力先ディレクトリ
- [DBFluteクライアント]/playsql/data/[dataLoadingType]/reversetsv/UTF-8
- ※dataLoadingTypeは、デフォルトでは ut
- ※出力エンコーディングはUTF-8固定なのでUTF-8ディレクトリ
- ファイル名
- cyclic_[セクション番号]_[セクション内テーブル連番]-[テーブル名].tsv
e.g. データ出力先 @Directory
dbflute_maihamadb
|-dfprop
|-...
|-playsql
| |-data
| | |-ut
| | | |-reversetsv
| | | | |-UTF-8
| | | | | |-cyclic_01_01-MEMBER.tsv
| | | | | |-cyclic_01_02-MEMBER_ADDRESS.tsv
| | | | | |-...
| | | | | |-loadingControlMap.dataprop
| | | | | |-reverse-data-result.dfmark
| | | |
...
同じディレクトリに reverse-data-result.dfmark というファイルが作成されます。どのTSVファイルに何件出力されたかなどの出力結果が記載されています。 その他、出力日時や実行時のプロパティ情報などが確認できます。
セクション番号とは?
TSVファイル名には必ずセクション番号が付与されます。 テーブル名から同じ系統のテーブルである、もしくは、FK参照のレベルが近いものが同じセクションになります。 テーブル間のまとまりをDBFluteが判断して番号を付与します。
セクション内のテーブル数は目安として 9 (デフォルト) になっているので、同じprefixのテーブル名でもセクションが分かれることはあります。
少々エクセルファイルの仕組みの名残感あるですが、テーブルがフラットに並ぶよりも見やすくなるという面もあり、TSVファイルでも採用されています。 (将来、セクションごとにディレクトリ分けして出力とかそういうのもあるかも!?)
sectionTableGuidelineLimitで、セクション内のテーブル数の目安を調整できます(@since 1.2.9)。 例えば、増やすことでテーブル追加時に発生しやすい既存テーブルのセクションの移動などを少なくして、差分を減らすことができるかもしれません。 (ですが、差分を気にするのであれば、そもそも既存ファイルに上書き出力のオプションを検討した方が良いかもしれません)
出力されるテーブルの順番は?
FK参照の上位順に出力 (デフォルト)
出力されるTSVファイルのテーブル順は、FK参照の上位から並びます。 ゆえに、ReplaceSchemaのときは親テーブルから順番に登録されるので、そのままデータ登録(ほぼ)できます。
"ほぼ" というのは、循環参照FKや自己参照FKなど、特殊なケースで上位を判定できないケースがあるかもしれないからです。 その場合は、手動でファイル名を修正して順番を調整してあげましょう。
ただ、新しいテーブルを一つ追加するだけでセクションが動くことがありますので、バージョン管理システムのコミット差分が多くなってしまいます。 DB変更が落ち着いて来た頃は、次に説明する既存ファイルに上書き出力する方式を検討しましょう。
既存ファイルに上書き出力 (オプション)
isOverrideExistingDataFile を true にすると、すでに出力先ディレクトリに存在するTSVファイルに上書き出力されるようになります(@since 1.2.9)。 ゆえに、新しいテーブルが追加されても、既存テーブルのファイル名は変わりません。
新しいテーブルは、新規ファイルとして cyclic_99_99_new_table-[テーブル名].tsv というファイルに出力されます。これは暫定の名前であり、99に入ってしまったものはFK順序を考慮して手動でファイル名を調整しましょう。
こちらの方式ではDBFluteのよるFK順序の考慮はされませんので、順番は人が管理することになります。 ゆえに、DB変更が激しいフェーズでは使わず(最初からは使わず)、DB変更がある程度落ち着いてきた頃にこちらの方式に移行するという使われ方が想定されます。 デフォルトからの移行であれば、既存ファイルはFK順序が考慮されているので、順番の調整は(ほとんど)新規テーブルのみとなります。
既存DBにReplaceSchemaを導入するケースであれば、最初の一回目だけ "デフォルトでFK順序のTSVファイル" を出力して、二回目以降は "既存ファイルに上書き" していくという使い方も良いでしょう。
DBFlute-1.2.8までは?
残念ながら、TSVファイルの出力で "既存ファイル上書き" がサポートされたのは 1.2.9 からです。 XLSファイルの方では昔からサポートされていましたが、TSVは後になってからのサポートとなりました。 (元々はXLSファイルがメインだったこともあり)
日付調整のoriginDateを自動同期
ReplaceSchemaの日付調整との連携
ReplaceSchemaにおけるデータ登録制御 (loadingControlMap.dataprop) の相対的な日付調整の基準日 (originDate) を、LoadDataReverse実行時に自動的に同期することができます。
日付調整の基準日は同期が必要
ReplaceSchemaで日付調整を利用している場合にそのまま LoadDataReverse すると、LoadDataReverseはDBに登録されているデータをそのまま出力しますから、調整された後の日付データが出力されてしまいます。 ゆえに、loadingControlMap.dataprop の originDate を更新しないと、その後の ReplaceSchema にてさらに二重で日付が調整されてしまうことになります。 originDate は LoadDataReverse を実行した日付にしてリセットするのがベストです。
自動でLoadDataReverseした日をoriginDateに
isSynchronizeOriginDate を true に設定すると、originDateが実行した日付に自動的に修正され、実行のたびにつどつど手動で修正する必要がなくなります。
同期処理の結果は、LoadDataReverse を実行したときに作成される出力結果の確認ドキュメント(reverse-data-result.dfmark)に記載されるので、 本当に同期されたかどうかを確認したいときは、そのファイルを見ると良いでしょう。
いろいろな考慮
commonにあるテーブルは出力対象外
ReplaceSchemaのディレクトリに直接出力する場合、common配下のデータで定義されているテーブルはLoadDataReverseでは出力されません。(TSVファイルにおいては @since 1.2.7)
でないと、ReplaceSchemaのデータ登録時にcommonのデータが重複してしまうためです。commonは手動で固定的に管理されるデータということで、循環テストデータの対象外です。
一つ前の出力結果をバックアップ
実行すると、出力ディレクトリ配下の既存のファイルは全て削除された上でデータが出力されます。 念のため、それら削除されるエクセルファイルを zip に固めたファイルを "出力ディレクトリ/backup" ディレクトリ配下にzipファイルで保存します。実行するたびに、このzipファイル自体を上書きしていきますので、二世代前のものは保存されません。
単なる念のためのものなので、gitを使っている場合はgitignoreすると良いでしょう。
利用方法 (エクセルファイル)
TSVファイルととても似ているので、違いだけを説明していきます。 (エクセルファイルをXLSファイルと表記することがあります)
dfpropで出力設定
DBFlute-1.2.8までは、デフォルトがXLSファイルです。
DBFlute-1.2.9以降では、documentMap.dfprop の loadDataReverseMap にて、isDelimiterDataBasis を false にしておきましょう。 (しばらくは変わらずデフォルトがXLSですが、そのうちTSVがデフォルトになる可能性が高いので)
e.g. 単に出力するだけの設定 @documentMap.dfprop
...
; loadDataReverseMap = map:{
# 1テーブルにおける出力するレコード数のリミット (-1は制限なし)
; recordLimit = -1
# ReplaceSchemaのディレクトリに直接出力するか? (循環テストデータ運用)
; isReplaceSchemaDirectUse = true
# それぞれのテーブルのデータを既存ファイルに上書き出力するかどうか?
; isOverrideExistingDataFile = false
# loadingControlMapのoriginDateを自動同期するか?
; isSynchronizeOriginDate = false
# TSVファイルで出力するかどうか? (DBFlute-1.2.9より)
; isDelimiterDataBasis = false
}
...
reversexlsに出力される
すると、DB上のデータがreversexls配下に出力されます(@since 1.0.4B)。 reversexlsは、通常のReplaceSchemaでのxlsディレクトリとは違い、LoadDataReverse専用のディレクトリとなります。
- 出力先ディレクトリ
- [DBFluteクライアント]/playsql/data/[dataLoadingType]/reversexls
- ※dataLoadingTypeは、デフォルトでは ut
- ファイル名
- cyclic-data-[セクション番号]-[セクションタイトル].xls
e.g. データ出力先 @Directory
dbflute_exampledb
|-dfprop
|-...
|-playsql
| |-data
| | |-ut
| | | |-reversexls
| | | | |-cyclic-data-01-MEMBER.xls
| | | | |-cyclic-data-02-PRODUCT.xls
| | | | |-...
| | | | |-loadingControlMap.dataprop
| | | | |-reverse-data-result.dfmark
| | | |
...
TSVと同様に reverse-data-result.dfmark というファイルが作成されます。 XLSファイルの場合は、どのXLSファイルにどのテーブルが入ってるのか?パッと見ではわからないですから、このファイルは重宝します。 テーブルを探すときはこちらのファイルを見ましょう。
一つのセクションで一つのXLSファイル
XLSでは一つのファイルに複数のテーブルのデータを保持できますので、そのまとまりをセクションで表現します。
ゆえに、一つのセクションとしてまとめられたテーブルのデータが一つのXLSファイルに入っています。 XLSファイルの名前もセクションタイトルが入ります。
XLSの限界超えるテーブル名だと?
エクセルのシート名に利用できる文字数に、(約)30文字までという制限があります。 それを超えるテーブル名がある場合は、ReplaceSchema の長いテーブル名対応の機能に沿った tableNameMap.dataprop を生成します。その場合のシート名は DBFlute が決め打った仮の名前になっているので、これを土台にする場合は手動で微調整すると良いでしょう。
XLSの限界超えるレコード数だと?
DBFluteがサポートしているエクセルの最大行数が 655xx なので、出力最大レコード数を 65000 で絞っています。もし、それを超える件数のデータが入っていて、かつ、recordLimit をそれ以上に設定した場合は、別途TSVデータとして出力されます(@since 0.9.8.3)。 TSVファイルは、reversetsvディレクトリに出力されます(@since 1.0.4B)。(1.0.4Bより前のバージョンでは、tsvディレクトリに出力されます)
TSV データへの出力は、一件ずつのフェッチ式になっているため、大量件数でもメモリ不足になることは基本的にありません。
XLSの限界超える文字数だと?
エクセルの一つのセルに格納できる文字数に、(約)32,767文字までという制限があります。 それを超えるカラムデータがある場合は、別シートに分割して出力されます。ReplaceSchema では、その分割されたデータは結合されて登録されます。 (@since 1.0.5C)
メモリ不足になるデータだと?
エクセルの最大行数を超えていない場合でも、全体的なテーブルの累積行数が多いとメモリ不足になる可能性があります。 (エクセルへの書き込みはライブラリの都合上、フェッチ式になっていないため)
その場合、タスクのメモリ設定を調整することで実行できるようになる可能性がありますが、 基本的には LoadDataReverse はそのような大容量のデータを落とすための機能ではありません。
細かい仕様
細かい仕様を把握して、どのような調整を行えば良いのか判断していきましょう。
- バイナリ型のデータは全て null で出力
- バイナリ型のデータはサポートされず、全て null として出力されます。
- テストデータとして必要な場合は、手動で準備します。
- JDBCタスクで取得されるテーブルが対象
- 自動生成対象外(JDBCタスクの時点で対象外)となっているテーブルのデータは出力されません。 そのテーブルのデータも出力したい場合は、一時的にそのテーブルも自動生成対象にする必要があります。
- ビュー(VIEW)は対象外
- ビュー(VIEW)はデータ出力対象外です。 当然のことと言えば当然ですが、ビューをシノニムの代わりに使っているような場合は、 この機能を利用するときだけ一時的にその参照先テーブルを自動生成対象にする必要があります。
- 追加スキーマのテーブルは対象外
- AdditionalSchema で定義されている追加スキーマのテーブルは対象外です。 そもそも ReplaceSchema で取り扱うスキーマはメインスキーマであることが基本なためです。
- シノニム(SYNONYM)は出力される
- シノニム(SYNONYM)はデータ出力対象です。ただし、シノニムが自動生成対象になっていることが前提です。 シノニムの参照先テーブルも自動生成対象となっている場合は、重複してデータが出力されますので、手動調整でどちらか片方を削除する必要があります。
- FK制約の順序考慮は厳密ではない
- テーブル間で複雑な参照関係を持っている場合に、FK制約の順序考慮が厳密にならない可能性があります。 その場合は、手動でエクセルのシートの順序を変えたり、エクセルファイル構成を変えたりと調整する必要があります。
- 厳密な精度は保証されない
- 例えば、日付型は以下のような形式で出力されます。
-
- DATE : yyyy/MM/dd (Oracleは HH:mm:ss も追加)
- TIMESTAMP : yyyy/MM/dd HH:mm:ss.SSS
- TIME : HH:mm:ss
- もし、TIMESTAMP型がこの書式を超える細かい精度を持っていると、その精度は失われます。
- その他の型は、単なるJDBCドライバの時点で文字列に変換したものを利用します。 JDBCドライバや文字列に直した時の特徴的な仕様によって、精度が失われる可能性はあります。
- これら精度を厳密に移行したい場合は、手動で調整する必要があります。 また、あくまでテストデータの移行というのを大前提としているので、実業務の本番データの移行などでは利用できません。
- その他、メジャーでない型はサポートされない
- 例えば、PostgreSQL の OID 型など、取扱いの難しいものなどはサポートされません。 明示的にサポートしていないわけではなく、そういった型がある場合、単にJDBCドライバの時点で文字列に変換したものが出力されます。 よって、JDBCドライバがその文字列を再解析できる場合は、ReplaceSchema でその文字列のままで登録できるかもしれません。
単に出力するだけの利用も
エクセル形式でデータを閲覧するためや、データを加工して多目的に利用するなど、ReplaceSchemaと関係なく "単にデータ出力するだけ" の利用もできます。
その場合は、documentMap.dfprop の loadDataReverseMap にて、isReplaceSchemaDirectUse は false にして実行します。
e.g. 単に出力するだけの設定 @documentMap.dfprop
...
; loadDataReverseMap = map:{
; recordLimit = -1
; isReplaceSchemaDirectUse = false
; isOverrideExistingDataFile = false
; isSynchronizeOriginDate = false
}
...
エクセルの出力先は playsql ではなく、DBFluteクライアントの output/doc/data 配下となります。こちらは、特に DBFlute のどの機能からも参照されません。
e.g. 単に出力するだけでのデータ出力先 @Directory
dbflute_exampledb
|-dfprop
|-output
| |-doc
| | |-data
| | | |-xls
| | | | |-reverse-data-01-MEMBER.xls
| | | | |-reverse-data-02-PRODUCT.xls
...
この場合、ReplaceSchemaへの直接出力のときとは違い、ReplaceSchemaのテストデータのcommon配下に定義されたテーブルであっても出力されます。 (もう ReplaceSchema とは関係がありません)
利用方法の歴史的変遷
機能が発展していく中で、利用方法がちょっとずつ変わってきた歴史があります。
- 0.9.9.7A 以前ではDocタスクにて (@until 0.9.9.7A)
- 0.9.9.7A 以前では、Manageタスクでの実行ではなく、プロパティの設定を有効にしてDocタスクを実行すると LoadDataReverse が実行されました。
- 1.0.4A 以前ではプロパティ名が違う (@until 1.0.4A)
- 1.0.4A 以前では、playsqlに直接出力するプロパティ isReplaceSchemaDirectUse が、isOutputToPlaySql となっていました。ちなみに、既存のエクセルファイルに上書きや、DateAdjustment の基準日の同期などのオプションは、このプロパティ名の変更と共にサポートされた機能です。 このとき、一気に LoadDataReverse が現場フィットするように改良されました。
- 1.0.4A 以前では共通カラムはオプション (@until 1.0.4A)
- 1.0.4A 以前では、デフォルトでは共通カラムは出力されません(@until 1.0.4A)。 共通カラムを出力したい場合は、documentDefinitionMap.dfprop の loadDataReverseMap の isContainsCommonColumn (@until 1.0.4A) を true にします。
- 1.0.4B 以降では、共通カラムは必ず出力されます。 共通カラムを除外するメリットが現場の利用状況を想定したときにあまりないと判断されたためです。
- 1.0.4B 以降ではreversexls/reversetsv (@since 1.0.4B)
- 循環テストデータ方式の場合の出力ディレクトリが変わりました。
- 1.2.9 以降ではTSVファイルが正式サポート (@since 1.2.9)
- 1.2.9 以降では、TSVファイルによる出力が正式にサポートされました。それまでも可能でしたが、あくまでおまけ的な扱いだったので、利用できない機能がありました。 特に大きなものとして、TSVファイルでも既存ファイルへの上書き出力がサポートされました。
厳密なデータダンプではない
この機能は、本番の業務データの移行などで利用できるデータダンプ(DataDump)ではありません。 人の目で見る、もしくは、手動での調整を入れて ReplaceSchema におけるエクセルデータの土台にする、という目的のものです。 もし、業務の一環としてのデータダンプを目的とするなら、もっとデータの精密度を高めたり、もっと色々な状況に対応できるようにしたりする必要があるでしょう。